In many applications of machine learning, the order in which data that is feed to a model is not relevant. For sequence prediction applications on the other hand, the order of the data matters. These applications require an explicit ordering of the data.
Types of Sequence Prediction
There of four types of sequence prediction: sequence continuation, sequence classification, sequence generation, and sequence to sequence translation.
Sequence Continuation
Sequence continuation deals with predicting the next value in a given input sequence. Example applications are weather forecasting or stock market predictions.
Sequence Classification
Sequence classification deals with predicting a class label for a given input sequence. Example applications are sentiment analysis of text or DNA classification.
Sequence Generation
Sequence Generation deals with generating a new output sequence. There are two versions of this depending of the type of input provided. If the input is also a sequence, then the new output sequence if created by iteratively performing a sequence continuation. In each sequence continuation step, a predicted value is generated. A new input sequence is created from the previous input sequence by copying the previous input sequence but without its first value and adding the newly predicted value at its end. This new input sequence is then used for the next sequence continuation step. Example applications of this type of sequence generation are text and music score generation. Alternatively, the input from which a new sequence is generated is a single value. An example application of this type of sequence generation is image captioning.
Sequence to Sequence Translation
Sequence to sequence translation deals with generating a new output sequence from a given input sequence. A common example application is text translation.
Sequence Prediction with Recurrent Neural Networks
As has been mentioned in the article on artificial neural networks, recurrent neural networks (RNN) are particularly useful for sequence prediction tasks since they are able to capture the sequential characteristics of data. RNNs can be employed in one of four basic setups that different from each other with respect to the type of input and output data that they handle.
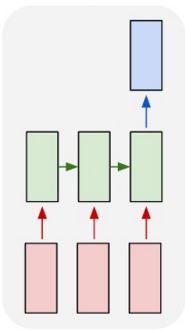
One to Many
In a One to Many setup, a RNN takes as input a single value and outputs a sequence. Such a setup can be used for a sequence generation task such as image caption.
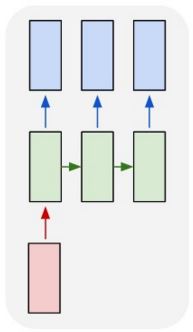
Many to One
In a Many to One setup, a RNN takes as input a sequence and outputs a single value. Such a setup can be used for sequence continuation and sequence classification tasks.
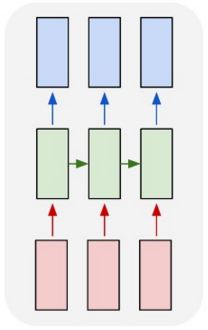
Many to Many with Identical Length of Input and Output
In a Many to Many setup, a RNN takes as input a sequence and outputs a sequence. The input and output sequences are synced and have the same length. Such a setup can be used for a video classification task in which each frame in the video is labelled individually.
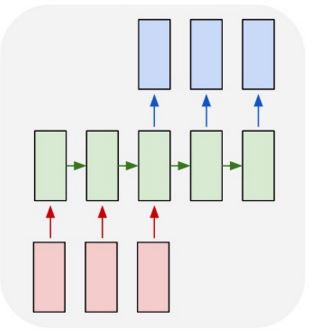
Many to Many with Non-Identical Length of Input and Output
In another Many to Many setup, a RNN takes as input a sequence and outputs a sequence. The input and output sequences are not synced and can have a different length. Such a setup can be used for sequence to sequence translation tasks.
Sequence Prediction with Convolutional Neural Networks
RRNs are experiencing an increasingly steep competition from convolutional neural networks when it comes to sequence prediction tasks. For operating on sequences of data, convolutional neural networks (CNN) employ one dimensional convolution along the length of the sequence. In addition, two important mechanisms have been introduced to CCNs to make them suitable for sequence prediction. These are: dilated kernels and causal convolution.
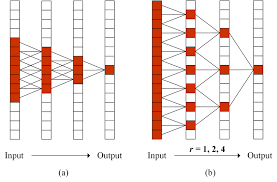
Dilated Kernels
Contrary to normal kernels, dilated kernels sample values in a matrix with gaps between the locations of the values. This allows the kernel to spread over a larger area of the matrix which, in the case of sequences, corresponds to a longer distance across the sequence. By employing kernels with dilations, a CCN can learn relationships between sequence values that lie far apart from each other without having to resort to unpractically large kernels.
Causal Convolution
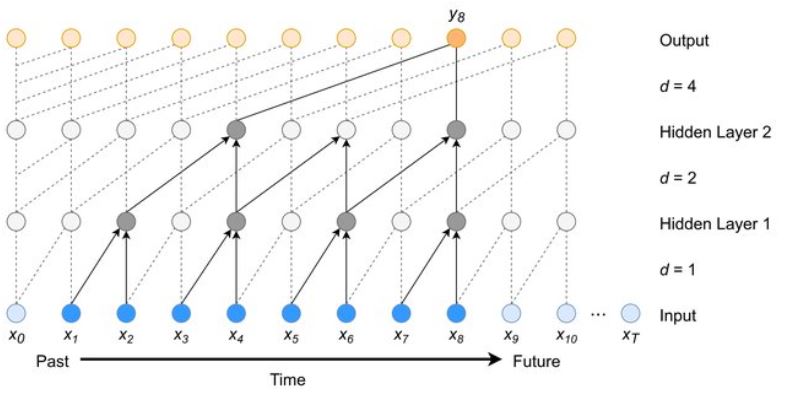
Causal convolution is a type of convolution in which only the values in the left half of the kernel are used in convolution whereas the kernel values in the right half are replaced by zero. This is achieved by masking the kernel. The purpose of masking the kernel is to conduct convolution only on values that are at the same position or further back in a sequence than the current value that is predicted. If the dimension along the sequence represents time, then what causal convolution achieves is to make it blind to values that lie in the future. This is essential for many sequence prediction tasks such as sequence continuation.
The reason that CNNs are starting to surpass RNNs in sequence prediction tasks is that CNNs can operate in parallel on input data (which RNNs can’t), they are good at exploiting local dependencies, and the distance between positions in a sequence is logarithmic. Convolutional Neural Networks can work in parallel because each value in an input sequence can be processed at the same time and does not necessarily depend on the previous values. The distance in position between output value and first value in an input sequence is in the order of log(N) which is much better than that of an RNN, in which the distance is in the order of N.
Transformer Model
The use of RNNs for sequence to sequence translation tasks is obsolete by now. This is partially because they have been superseded in efficiency by CNNs. But also because of the introduction of attention mechanisms. These mechanisms help with preserving the influence of important values even if they are located far back in an input sequence. Attention mechanisms have been introduced in the context of text to text translation. There, models with attention have been shown to significantly surpass models without.
Transformer models are models that employ multiple forms of attention. The level of sophistication of this approach exceeds the scope of this article. Readers interested in this topic can find more information for instance in an article by Gaurav Ghati.