Generative Adversarial Networks (GANs) have become famous also among a general people for their capability to generate photorealistic images, for instance of human faces. The following article introduces GANs that generate images. Nevertheless, many aspects described here also apply for GANs that generate different types of data.

Generator and Discriminator Model
GANs consist of two models, one named Generator and the other named Discriminator. The Generator takes as input a vector of random values and produces as output a synthetic image. The Discriminator takes as input an image and produces as output a label. The input image can either be produced by the Generator or be taken from a dataset of real images. The label indicates whether the Discriminator identifies the input image as fake (produced by the Generator) or as real (an image from the dataset). Both the Generator and the Discriminator are typically implemented as neural networks.
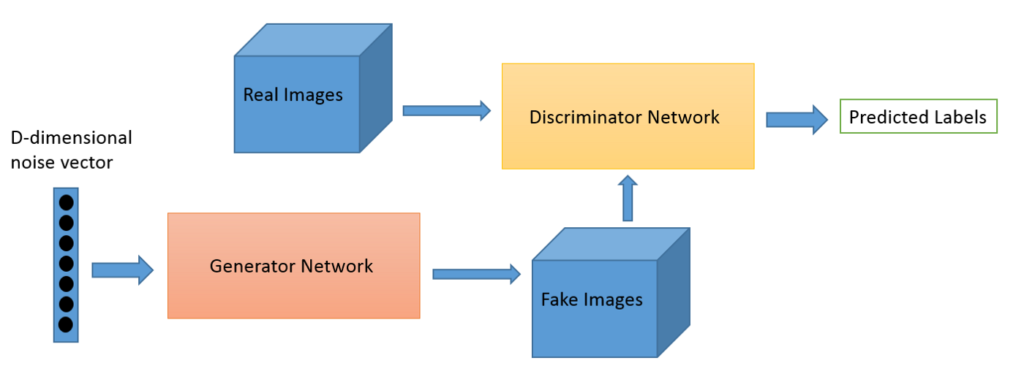
Network Architecture
For the application of image synthesis, the Generator and Discriminator networks are implemented as convolutional neural networks.
The arrangement of layers in a Discriminator is identically to that of a model used for image classification. The layers conduct a series of convolution operations to successively decrease the resolution and increase the number of channels of feature maps. The last feature map is then flattened into a one-dimensional vector. This vector is then processed by layers of a conventional artificial neuronal network before a class label is finally predicted.

The arrangement of layers in a Generator more or less mirrors that of a Discriminator. Here, the first part consists of a conventional neural network. The second part consists of a convolutional neural network whose layers conduct a series of deconvolution operations to successively increase the resolution and decrease the number of channels of feature maps until they match those of the images in the dataset. For data to pass from the conventional neural network into the convolutional neural network, it needs to be un-flattened. Un-flattening is the opposite operation to flattening, i.e. a one-dimensional vector is converted into a two-dimensional feature map.

Deconvolution
Deconvolution represents the opposite of convolution. In convolution, a dot product is calculated between a kernel and an region of a feature map with the result a single scalar value. In deconvolution, a kernel is employed to convert a single scalar value into a region of a feature map.

Similarly inverted versions also exist for other types of layers that are typically used in convolutional neural networks such as pooling layers.
Competition
During training, these two models compete with each other. The Generator tries to fool the Discriminator into “believing” that the generated synthetic images represent real images. In order to succeed in this, the Generator has to learn the statistical distribution of images so that it becomes better at generating synthetic images that are indistinguishable for the Discriminator from real images. The Discriminator on the other hand tries to identify the images generated by the Generator as fake and those from the dataset as real. In order to succeed in this, the Discriminator has to learn a classification task. This situation resembles a typical case used in Game Theory, in that the Discriminator and Generator can be understood as rational agents that compete with each other, each trying to come up with a strategy to beat the other agent. By adjusting their respective strategies the agents eventually reach a Nash Equilibrium. At this point, the agents consider their strategies optimal and no longer change them. In the case of a GAN, a Nash Equilibrium is reached, when the Generator always succeeds in fooling the Discriminator no matter how good the Discriminator has become in distinguishing between real and fake images.
Training
During training, the Discriminator and Generator take turns in updating their trainable parameters.
When training the Discriminator, the trainable parameters of the Generator are fixed. The Discriminator is provided with images that are either real or synthetic alongside the corresponding labels. During training, the Discriminator tries to minimise the error that it makes in predicting these labels.

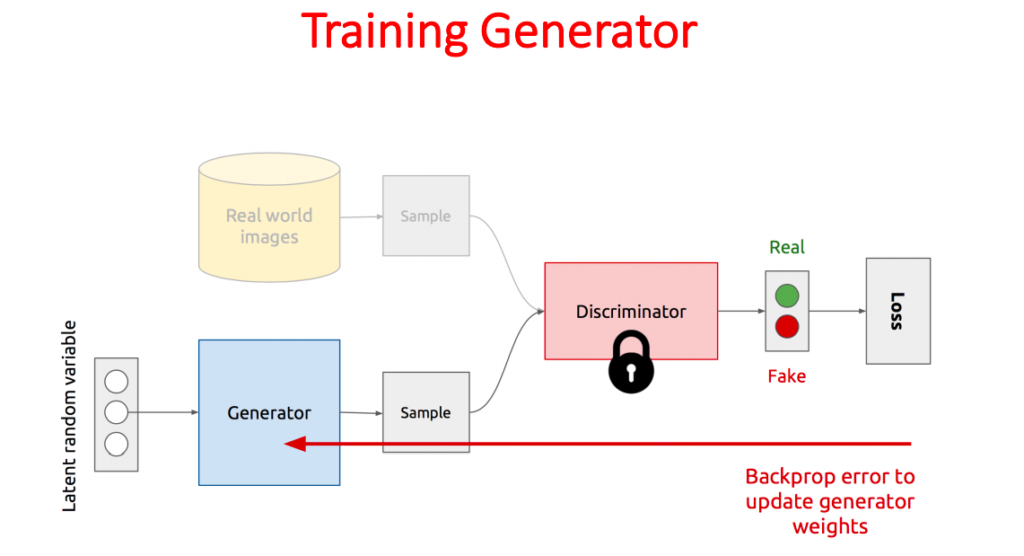
When training the Generator, the trainable parameters of the Discriminator are fixed. The Generator is provided with vectors containing random values. It generates synthetic images from these vectors and passes these images as input to the Discriminator which in turn labels them as either real or fake. During training, the Generator tries to maximise the error that the Discriminator makes in predicting these labels.
Latent Vector
The vector containing random numbers that is provided as input to the Generator for generating synthetic images plays an important role. This vector plays represents an encoding for a synthetic image. An encoding can also be thought of as a latent code for a synthetic image. Latent codes represent the most interesting aspect of GANs, since conventional vector arithmetic can be conducted on them to create new synthetic images. This topic will be further elaborated in the article on Autoencoders.