Summary
The following tutorial introduces a system entitled “Granular Dance” that can generate synthetic sequences of dance poses of arbitrary length. This system combines an adversarial autoencoder with a method for sequence concatenation. The autoencoder model uses a combination of conventional neural network (ANN) and long short term memory (LSTM) layers to create short pose sequences. The concatenation method blends joint rotations to create smooth transitions between these short pose sequences. The article focuses on the explanation of the blending mechanism and provides some examples how the latent space of pose sequence encodings can be navigated to discover potentially interesting synthetic pose sequences.
This tutorial forms part of a series of tutorials on using PyTorch to create and train generative deep learning models. The code for these tutorials is available here.
After 400 epochs of training, the pose sequences reconstructed by the autoencoder look like this when rendered as skeleton animation.
Sequence Blending
This article focuses on the explanation of the sequence blending method. All other aspects such as the creation of the dataset, the model architectures, and the training have been explained in a previous article on “Pose Sequence Generation with an Adversarial Autoencoder”.
For those who have experimented with the code examples in the previous article, it will have become apparent that the concatenated sequences contain discontinuities at the position of the concatenation. To avoid such discontinuities, “Granular Dance” employs a blending mechanism between successive sequences. The sequence blending mechanism is inspired by two methods from computer music that combine short sound fragments to generate longer sounds: Granular Synthesis and Concatenative Synthesis. In Granular Dance, a window function (Hanning) is superimposed on a pose sequence. But rather than controlling an amplitude as for audio, this function blends the joint orientations of the overlapping pose sequences by using spherical linear interpolation (SLERP).
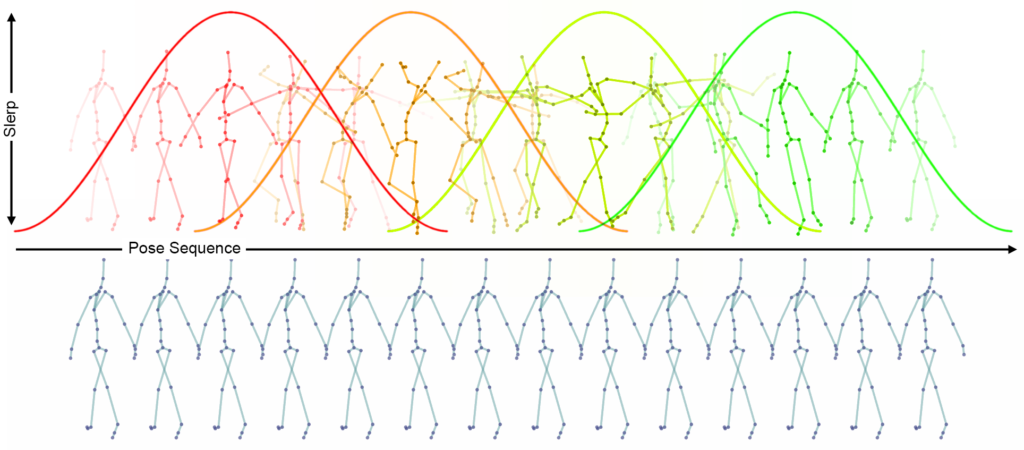
The principle of sequence blending employed by Granular Dance involves the following steps:
- A Hanning window is created with a length that is equal to the size of the pose sequence that the autoencoder works with.
- An empty output pose sequence that eventually holds the concatenated pose sequence is created.
- The output pose sequence is populated with an arbitrary pose that provides initial joint angles for interpolation.
- Then for every input pose sequence, a quaternion SLERP is conducted between the corresponding excerpt of the output pose sequence and an input pose sequence. Quaternion SLERP is calculated pose by pose for all joint rotations by stepping along the two pose sequences and taking the SLERP interpolation value from the Hanning window. This results in a pose sequence which is then added at the corresponding position to the output pose sequence.
The code for conducting sequence blending appears in the function named “decode_sequence_encodings”. This function takes the following arguments: a list of encodings of pose sequences, the size of the overlap between successive pose sequences, a base pose for initially populating the resulting pose sequence, and a file name under which the resulting pose sequence is saved as skeleton animation. This function is defined as follows:
def decode_sequence_encodings(sequence_encodings, seq_overlap, base_pose, file_name):
decoder.eval()
seq_env = np.hanning(sequence_length)
seq_excerpt_count = len(sequence_encodings)
gen_seq_length = (seq_excerpt_count - 1) * seq_overlap + sequence_length
gen_sequence = np.full(shape=(gen_seq_length, joint_count, joint_dim), fill_value=base_pose)
for excerpt_index in range(len(sequence_encodings)):
latent_vector = sequence_encodings[excerpt_index]
latent_vector = np.expand_dims(latent_vector, axis=0)
latent_vector = torch.from_numpy(latent_vector).to(device)
with torch.no_grad():
excerpt_dec = decoder(latent_vector)
excerpt_dec = torch.squeeze(excerpt_dec)
excerpt_dec = excerpt_dec.detach().cpu().numpy()
excerpt_dec = np.reshape(excerpt_dec, (-1, joint_count, joint_dim))
gen_frame = excerpt_index * seq_overlap
for si in range(sequence_length):
for ji in range(joint_count):
current_quat = gen_sequence[gen_frame + si, ji, :]
target_quat = excerpt_dec[si, ji, :]
quat_mix = seq_env[si]
mix_quat = slerp(current_quat, target_quat, quat_mix )
gen_sequence[gen_frame + si, ji, :] = mix_quat
gen_sequence = torch.from_numpy(gen_sequence)
gen_sequence = gen_sequence.view((-1, 4))
gen_sequence = nn.functional.normalize(gen_sequence, p=2, dim=1)
gen_sequence = gen_sequence.view((gen_seq_length, joint_count, joint_dim))
gen_sequence = torch.unsqueeze(gen_sequence, dim=0)
gen_sequence = gen_sequence.to(device)
zero_trajectory = torch.tensor(np.zeros((1, gen_seq_length, 3), dtype=np.float32))
zero_trajectory = zero_trajectory.to(device)
skel_sequence = skeleton.forward_kinematics(gen_sequence, zero_trajectory)
skel_sequence = skel_sequence.detach().cpu().numpy()
skel_sequence = np.squeeze(skel_sequence)
view_min, view_max = utils.get_equal_mix_max_positions(skel_sequence)
skel_images = poseRenderer.create_pose_images(skel_sequence, view_min, view_max, view_ele, view_azi, view_line_width, view_size, view_size)
skel_images[0].save(file_name, save_all=True, append_images=skel_images[1:], optimize=False, duration=33.0, loop=0)
decoder.train()Generate and Visualise Pose Sequences
As in the previous article on “Pose Sequence Generation with an Adversarial Autoencoder”, several convenience functions are provided for reconstructing and visualising sequences of poses. The previously described function “decode_sequence_encodings” is one of them. All the other convenience functions are identical with those in the previous article. These other functions are skipped here.
In the following, some examples of using the convenience functions to experiment with pose sequences and pose sequence encodings are presented.
Create an Animation for a Single Original Pose Sequence
A single original pose sequence can be obtained and saved as animation as follows
seq_index = 100
create_ref_sequence_anim(seq_index, "results/anims/orig_sequence_{}.gif".format(seq_index))Create an Animation for a Single Reconstructed Pose Sequence
A single pose sequence can be reconstructed and saved as animation as follows:
seq_index = 100
create_rec_sequence_anim(seq_index, "results/anims/rec_sequence_{}.gif".format(seq_index))The next examples all employ sequence blending. For this, two settings have to be specified: the size of the overlap between successive pose sequences and the pose to be used to initially populate the output pose sequence. This can be done as follows:
seq_overlap = 32
base_pose = np.reshape(pose_sequence[0], (joint_count, joint_dim))
Create an Animation from Several Reconstructed Pose Sequences
A list of pose sequences can be reconstructed and saved as animation as follows:
start_seq_index = 100
end_seq_index = 612
seq_indices = [ frame_index for frame_index in range(start_seq_index, end_seq_index, seq_overlap)]
seq_encodings = encode_sequences(seq_indices)
decode_sequence_encodings(seq_encodings, seq_overlap, base_pose, "results/anims/rec_sequences_{}-{}.gif".format(start_seq_index, end_seq_index))
Create an Animation from a Random Walk in Latent Space
In a more interesting example, a single pose sequence is encoded and the encoding is used as starting point for a random walk within latent space. The random walk generates a list of increasingly randomised pose sequence encodings which are then decoded into pose sequences, concatenated and saved as animation.
start_seq_index = 4000
seq_frame_count = 32
seq_indices = [start_seq_index]
seq_encodings = encode_sequences(seq_indices)
for index in range(0, seq_frame_count - 1):
random_step = np.random.random((latent_dim)).astype(np.float32) * 2.0
seq_encodings.append(seq_encodings[index] + random_step)
decode_sequence_encodings(seq_encodings, seq_overlap, base_pose, "results/anims/seq_randwalk_{}_{}.gif".format(start_seq_index, seq_frame_count))
Create an Animation by Following a Trajectory in Latent Space with an Offset
In this example, a list of pose sequences that follow each other in the original motion capture recording is encoded into a list of latent vectors. These latent vectors represent a trajectory in latent space. This trajectory is followed at an offset by adding a vector to each pose sequence encoding. The resulting encodings are then decoded into pose sequences, concatenated and saved as animation.
seq_start_index = 4000
seq_end_index = 5000
seq_indices = [ seq_index for seq_index in range(seq_start_index, seq_end_index, seq_overlap)]
seq_encodings = encode_sequences(seq_indices)
offset_seq_encodings = []
for index in range(len(seq_encodings)):
sin_value = np.sin(index / (len(seq_encodings) - 1) * np.pi * 4.0)
offset = np.ones(shape=(latent_dim), dtype=np.float32) * sin_value * 4.0
offset_seq_encoding = seq_encodings[index] + offset
offset_seq_encodings.append(offset_seq_encoding)
decode_sequence_encodings(offset_seq_encodings, seq_overlap, base_pose, "results/anims/seq_offset_{}-{}.gif".format(seq_start_index, seq_end_index))
Create an Animation by Interpolating Between Pose Sequence Encodings
Two pose sequences are encoded and new encodings are created by gradually interpolating between the initial pose sequence encodings. Each interpolated encoding is decoded into a pose sequence. All these pose sequences are concatenated and saved as animation.
seq1_start_index = 1000
seq1_end_index = 2000
seq2_start_index = 4000
seq2_end_index = 5000
seq1_indices = [ seq_index for seq_index in range(seq1_start_index, seq1_end_index, seq_overlap)]
seq2_indices = [ seq_index for seq_index in range(seq2_start_index, seq2_end_index, seq_overlap)]
seq1_encodings = encode_sequences(seq1_indices)
seq2_encodings = encode_sequences(seq2_indices)
mix_encodings = []
for index in range(len(seq1_encodings)):
mix_factor = index / (len(seq1_indices) - 1)
mix_encoding = seq1_encodings[index] * (1.0 - mix_factor) + seq2_encodings[index] * mix_factor
mix_encodings.append(mix_encoding)
decode_sequence_encodings(mix_encodings, seq_overlap, base_pose, "results/anims/seq_mix_{}-{}_{}-{}.gif".format(seq1_start_index, seq1_end_index, seq2_start_index, seq2_end_index))