Several machine learning examples provided here use data obtained through motion capture. Some example motion capture recordings are available here. For these recordings, a marker based optical motion capture system (Qualisys, 12 cameras) provided by the dance company Cie Gilles Jobin was used. The recordings are of a solo dancer who was improvising according to various movement qualities. Some information about the role and types of movement qualities used in contemporary dance is available here.
The motion capture data is based on a skeleton representation of the dancer that contains 64 joints, out of which 40 joints are used to represent the dancer’s hands. Working with this full set of joints has turned out to be challenging for machine learning since such a large number of hand joints dominate the loss function at the expense of the remaining joints. For this reason, the dataset created from motion capture contains a smaller number of joints with all hand joints except those of the middle finger removed. The reduced skeleton contains 35 joints.
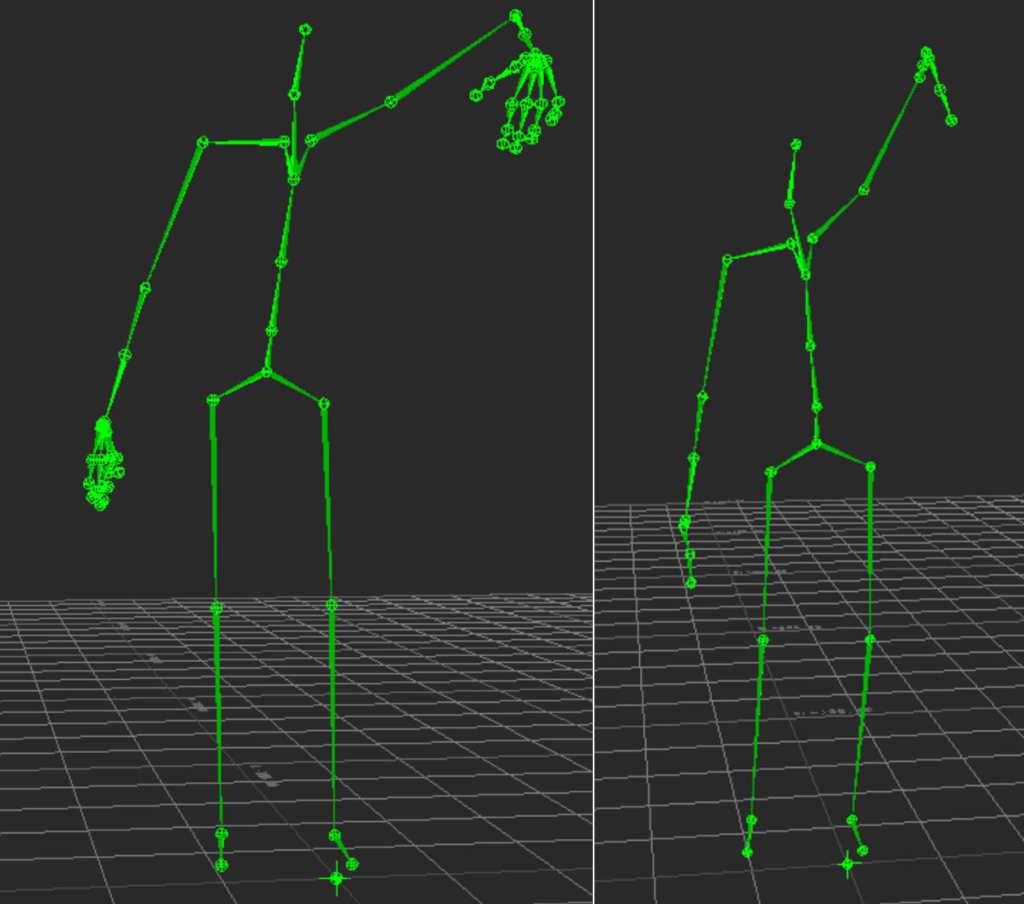
The reduced skeleton contains the following joints.
joint 0 : Hips
joint 1 : Spine
joint 2 : Spine1
joint 3 : Spine2
joint 4 : Neck
joint 5 : Head
joint 6 : Head_Nub
joint 7 : LeftShoulder
joint 8 : LeftArm
joint 9 : LeftForeArm
joint 10 : LeftForeArmRoll
joint 11 : LeftHand
joint 12 : LeftInHandMiddle
joint 13 : LeftHandMiddle1
joint 14 : LeftHandMiddle2
joint 15 : LeftHandMiddle2_Nub
joint 16 : RightShoulder
joint 17 : RightArm
joint 18 : RightForeArm
joint 19 : RightForeArmRoll
joint 20 : RightHand
joint 21 : RightInHandMiddle
joint 22 : RightHandMiddle1
joint 23 : RightHandMiddle2
joint 24 : RightHandMiddle2_Nub
joint 25 : LeftUpLeg
joint 26 : LeftLeg
joint 27 : LeftFoot
joint 28 : LeftToeBase
joint 29 : LeftToeBase_Nub
joint 30 : RightUpLeg
joint 31 : RightLeg
joint 32 : RightFoot
joint 33 : RightToeBase
joint 34 : RightToeBase_NubThe topology of the skeleton is as follows:
joint 0 children: 1 25 30
joint 1 children: 2
joint 2 children: 3
joint 3 children: 4 7 16
joint 4 children: 5
joint 5 children: 6
joint 6 children:
joint 7 children: 8
joint 8 children: 9
joint 9 children: 10
joint 10 children: 11
joint 11 children: 12
joint 12 children: 13
joint 13 children: 14
joint 14 children: 15
joint 15 children:
joint 16 children: 17
joint 17 children: 18
joint 18 children: 19
joint 19 children: 20
joint 20 children: 21
joint 21 children: 22
joint 22 children: 23
joint 23 children: 24
joint 24 children:
joint 25 children: 26
joint 26 children: 27
joint 27 children: 28
joint 28 children: 29
joint 29 children:
joint 30 children: 31
joint 31 children: 32
joint 32 children: 33
joint 33 children: 34
joint 34 children:The original mocap recordings are stored in the Autodesk Filmbox Format (FBX) and the Biovision Hierarchy Animation File Format (BVH). The data used for machine learning is in a custom format. This format is a “pickled” serialised Python dictionary. The dictionary stores motion capture data as follows:
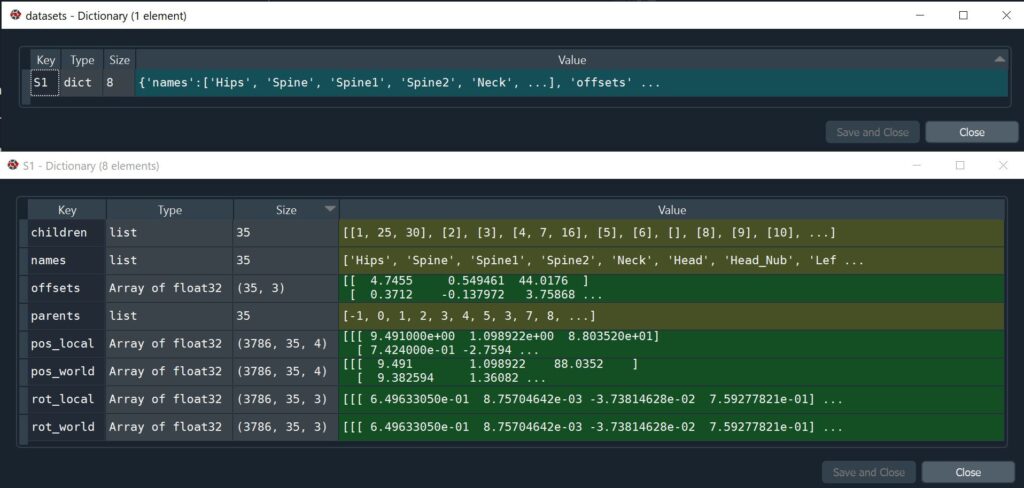
The top level dictionary contains one key-value pair per dancer. Since there is only one dancer in all recordings, there is also only one key-value pair. The key used here is “S1” which is an abbreviation for subject 1. The value is another dictionary. This second dictionary stores joint names, the parent joint indices, parent children relationships among joints, the joint offsets, local joint coordinates, world joint coordinates, local joint rotations as quaternions, world joint rotations as quaternions.
Such a dictionary can be created from any motion capture recording that is stored in BVH format. A small python tool has been developed for converting from BVH format into the dictionary format. This tool is available here. To perform a conversion, the python script has to be run from the command line as follows:
python main_bvhconv.py --input <mocap file in bvh format> --output <mocap file in pickled dictionary format>