Summary
The following tutorial introduces the use of a simple generative adversarial network for generating synthetic dance poses. This model can be trained on motion capture data. The model uses conventional neural network layers (ANN) to create poses.
This tutorial forms part of a series of tutorials on using PyTorch to create and train generative deep learning models. The code for these tutorials is available here.
After 400 epochs of training, the model generates pose that look like this when rendered as skeletons.
Imports
The following modules need to be available and imported for this example. The “common” module with all its submodules is included when downloading the tutorial files.
import torch
from torch.utils.data import Dataset
from torch.utils.data import DataLoader
from torch import nn
from collections import OrderedDict
import os, sys, time, subprocess
import numpy as np
sys.path.append("../..")
from common import utils
from common.skeleton import Skeleton
from common.mocap_dataset import MocapDataset
from common.quaternion import qmul, qnormalize_np, slerp
from common.pose_renderer import PoseRenderer
import matplotlib.pyplot as pltCompute Device
If a GPU is available for running the model, this device can be selected as follows.
device = 'cuda' if torch.cuda.is_available() else 'cpu'
print('Using {} device'.format(device))Read Motion Capture Data
The file from which data is loaded is a “pickled” dictionary containing motion capture data. More information about this format is available here. The MocapDataset class is used to import such a file. Information about the MocapDataset class is available here. In the following code excerpt, a motion capture file is loaded and a sequence of poses represented by joint rotations (quaternions) is obtained.
mocap_data_path = "../../data/Mocap/MUR_Nov_2021/MUR_PolytopiaMovement_Take2_mb_proc_rh.p"
mocap_fps = 50
# load mocap data
mocap_data = MocapDataset(mocap_data_path, fps=mocap_fps)
if device == 'cuda':
mocap_data.cuda()
mocap_data.compute_positions()
# gather skeleton info
skeleton = mocap_data.skeleton()
skeleton_joint_count = skeleton.num_joints()
skel_edge_list = utils.get_skeleton_edge_list(skeleton)
# obtain pose sequence
subject = "S1"
action = "A1"
pose_sequence = mocap_data[subject][action]["rotations"]
The edge list obtained from a skeleton can be passed to the constructor of the PoseRenderer class. An instance of the this class can be used for visualising poses. More information about the PoseRenderer class is available here. An instance of the PoseRenderer class can be created as follows:
skel_edge_list = utils.get_skeleton_edge_list(skeleton)
poseRenderer = PoseRenderer(skel_edge_list)Create Dataset
To create a dataset from the motion capture data that can be used for training, several steps are undertaken: remove sequence excerpts in which poses are invalid or otherwise unsuitable for training, collect information about the remaining pose sequence, declare and define a Dataset class to hold the data, split the data into a training and test set, and instantiate DataLoaders from the training and test set.
The removal of unwanted sequence excerpts and the collection of information about the remaining pose sequence is conducted as follows:
mocap_valid_frame_ranges = [ [ 500, 6500 ] ]
poses = []
for valid_frame_range in mocap_valid_frame_ranges:
frame_range_start = valid_frame_range[0]
frame_range_end = valid_frame_range[1]
poses += [pose_sequence[frame_range_start:frame_range_end]]
poses = np.concatenate(poses, axis=0)
pose_count = poses.shape[0]
joint_count = poses.shape[1]
joint_dim = poses.shape[2]
pose_dim = joint_count * joint_dim
poses = np.reshape(poses, (-1, pose_dim))A custom dataset class for poses is created by subclassing the Dataset class.
class PoseDataset(Dataset):
def __init__(self, poses):
self.poses = poses
def __len__(self):
return self.poses.shape[0]
def __getitem__(self, idx):
return self.poses[idx, ...]This custom dataset class is instantiated as follows:
full_dataset = PoseDataset(poses)This dataset contains all data. The dataset can be split into two datasets, one for training and one for testing, as follows:
test_percentage = 0.2
dataset_size = len(full_dataset)
test_size = int(test_percentage * dataset_size)
train_size = dataset_size - test_size
train_dataset, test_dataset = torch.utils.data.random_split(full_dataset, [train_size, test_size])
train_dataloader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
test_dataloader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False)DataLoaders are created from these two datasets as follows:
batch_size = 16
train_dataloader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
test_dataloader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False)Create Models
As has been explained in the previous article on creating synthetic images with a GAN, both a Generator model and a Critique model need to be implemented. The Generator model takes as input a tensor containing noise and produces as output a tensor the represents synthetic poses. The Critique takes as input a tensor representing poses and produces as output a tensor that classifies the poses as ether real or fake. Both models employ only conventional artificial neural networks (ANN).
Create Critique Model
For converting input poses into output classes, the Critique model passes the input poses in the form of a one dimensional feature vector through several ANN layers. These layers successively reduce the dimension of the feature vector down to 1. Each ANN layer with the exception of the last one is followed by a leaky ReLU activation function. The last ANN layer is followed by a Softmax activation function to obtain normalised class probabilities.
The class definition of the Critique model is as follows:
class Critique(nn.Module):
def __init__(self, pose_dim, dense_layer_sizes):
super().__init__()
self.pose_dim = pose_dim
self.dense_layer_sizes = dense_layer_sizes
# create dense layers
dense_layers = []
dense_layers.append(("encoder_dense_0", nn.Linear(self.pose_dim, self.dense_layer_sizes[0])))
dense_layers.append(("encoder_dense_relu_0", nn.ReLU()))
dense_layer_count = len(dense_layer_sizes)
for layer_index in range(1, dense_layer_count):
dense_layers.append( ("encoder_dense_{}".format(layer_index), nn.Linear(self.dense_layer_sizes[layer_index-1], self.dense_layer_sizes[layer_index] ) ) )
dense_layers.append( ("encoder_dense_relu_{}".format( layer_index ), nn.ReLU() ) )
dense_layers.append( ( "encoder_dense_{}".format( len( self.dense_layer_sizes ) ), nn.Linear( self.dense_layer_sizes[-1], 1) ) )
dense_layers.append( ( "encoder_dense_sigmoid_{}".format( len( self.dense_layer_sizes ) ), nn.Sigmoid() ) )
self.dense_layers = nn.Sequential(OrderedDict(dense_layers))
def forward(self, x):
#print("x 1 ", x.shape
yhat = self.dense_layers(x)
#print("yhat ", yhat.shape)
return yhatThe constructor of the Critique model class takes two arguments: the dimensions of a pose and a sequence of unit counts for the ANN layers (with the unit count of 1 for the last layer missing since this layer is added anyway). The model class can be instantiated as follows:
crit_dense_layer_sizes = [ 128, 64, 16 ]
critique = Critique(pose_dim, crit_dense_layer_sizes).to(device)The shapes of the input and output tensors for this model are as follows:
- input tensor: batch_size x pose_dim
- output tensor: batch_size x 1
Create Generator Model
For generating synthetic poses from a one dimensional vector of random values, the Generator model passes the noise vector through ANN layers. These layers successively increase the dimension of the noise vector. Each ANN layer with the exception of the last one is also followed by a ReLU activation function. The last ANN layer is not followed by an activation function.
The class definition of the Generator model is as follows:
class Generator(nn.Module):
def __init__(self, pose_dim, latent_dim, dense_layer_sizes):
super(Generator, self).__init__()
self.pose_dim = pose_dim
self.latent_dim = latent_dim
self.dense_layer_sizes = dense_layer_sizes
# create dense layers
dense_layers = []
dense_layers.append(("generator_dense_0", nn.Linear(latent_dim, self.dense_layer_sizes[0])))
dense_layers.append(("generator_relu_0", nn.ReLU()))
dense_layer_count = len(self.dense_layer_sizes)
for layer_index in range(1, dense_layer_count):
dense_layers.append(("generator_dense_{}".format(layer_index), nn.Linear(self.dense_layer_sizes[layer_index-1], self.dense_layer_sizes[layer_index])))
dense_layers.append( ( "generator_dense_relu_{}".format( layer_index ), nn.ReLU() ) )
dense_layers.append( ( "generator_dense_{}".format( len( self.dense_layer_sizes ) ), nn.Linear( self.dense_layer_sizes[-1], self.pose_dim) ) )
self.dense_layers = nn.Sequential(OrderedDict(dense_layers))
def forward(self, x):
#print("x 1 ", x.size())
# dense layers
yhat = self.dense_layers(x)
#print("yhat ", yhat.size())
return yhatThe constructor of the Generator model class takes three arguments: the pose dimension, the latent dimension of the pose encoding, and a sequence of unit counts for the ANN layers (with the unit count for the last layer missing since this corresponds to the dimension of a pose and this layer is added anyway). The model class can be instantiated as follows:
latent_dim = 8
generator = Generator(pose_dim, latent_dim, gen_dense_layer_sizes).to(device)The shapes of the input and output tensors for this model are as follows:
- input tensor: batch_size x latent_dim
- output tensor: batch_size x pose_dim
Optimisers and Loss Functions
The two optimisers and the loss function for the Critique model are identical to those used for the image generating GAN. What differs are the loss functions for the Generator. Two separate loss functions are used for the Generator. The loss function named “gen_crit_loss” is identical to the one named “gen_loss” in the image generating example. A second loss function named “gen_norm_loss” is used to quantify the deviation of the generated joint rotations from unit quaternions. The second loss function is defined as follows:
def gen_norm_loss(yhat):
_yhat = yhat.view(-1, 4)
_norm = torch.norm(_yhat, dim=1)
_diff = (_norm - 1.0) ** 2
_loss = torch.mean(_diff)
return _lossThese two individual loss functions are called by the loss function named “gen_loss”. This loss function calculates a single loss value from a weighted sum of the two individual loss values. The function is defined as follows:
gen_norm_loss_scale = 0.1
gen_crit_loss_scale = 1.0
def gen_loss(yhat, crit_fake_output):
_norm_loss = gen_norm_loss(yhat)
_crit_loss = gen_crit_loss(crit_fake_output)
_total_loss = 0.0
_total_loss += _norm_loss * gen_norm_loss_scale
_total_loss += _crit_loss * gen_crit_loss_scale
return _total_loss, _norm_loss, _crit_lossTraining and Testing Functions
There is again a total of four different functions for conducting the training and testing steps for the Critique and Generator. These functions are extremely similar to the ones used for image generation. For this reason, the code for defining these functions is included here without further explanations.
def crit_train_step(real_poses, random_encodings):
critique_optimizer.zero_grad()
with torch.no_grad():
fake_output = generator(random_encodings)
real_output = real_poses
crit_real_output = critique(real_output)
crit_fake_output = critique(fake_output)
_crit_loss = crit_loss(crit_real_output, crit_fake_output)
_crit_loss.backward()
critique_optimizer.step()
return _crit_loss
def crit_test_step(real_poses, random_encodings):
with torch.no_grad():
fake_output = generator(random_encodings)
real_output = real_poses
crit_real_output = critique(real_output)
crit_fake_output = critique(fake_output)
_crit_loss = crit_loss(crit_real_output, crit_fake_output)
return _crit_loss
def gen_train_step(random_encodings):
generator_optimizer.zero_grad()
generated_poses = generator(random_encodings)
crit_fake_output = critique(generated_poses)
_gen_loss, _norm_loss, _crit_loss = gen_loss(generated_poses, crit_fake_output)
_gen_loss.backward()
generator_optimizer.step()
return _gen_loss, _norm_loss, _crit_loss
def gen_test_step(random_encodings):
with torch.no_grad():
generated_poses = generator(random_encodings)
crit_fake_output = critique(generated_poses)
_gen_loss, _norm_loss, _crit_loss = gen_loss(generated_poses, crit_fake_output)
return _gen_loss, _norm_loss, _crit_loss
The function named “train” performs the actual training of the two models by calling the train and test step functions repeatedly. This function is also almost identical to the one used for image generation. The function is defined as follows:
def train(train_dataloader, test_dataloader, epochs):
loss_history = {}
loss_history["gen train"] = []
loss_history["gen test"] = []
loss_history["crit train"] = []
loss_history["crit test"] = []
loss_history["gen crit"] = []
loss_history["gen norm"] = []
for epoch in range(epochs):
start = time.time()
crit_train_loss_per_epoch = []
gen_train_loss_per_epoch = []
gen_norm_loss_per_epoch = []
gen_crit_loss_per_epoch = []
for train_batch in train_dataloader:
train_batch = train_batch.to(device)
random_encodings = torch.randn((train_batch.shape[0], latent_dim)).to(device)
# start with critique training
_crit_train_loss = crit_train_step(train_batch, random_encodings)
_crit_train_loss = _crit_train_loss.detach().cpu().numpy()
crit_train_loss_per_epoch.append(_crit_train_loss)
# now train the generator
for iter in range(2):
_gen_loss, _gen_norm_loss, _gen_crit_loss = gen_train_step(random_encodings)
_gen_loss = _gen_loss.detach().cpu().numpy()
_gen_norm_loss = _gen_norm_loss.detach().cpu().numpy()
_gen_crit_loss = _gen_crit_loss.detach().cpu().numpy()
gen_train_loss_per_epoch.append(_gen_loss)
gen_norm_loss_per_epoch.append(_gen_norm_loss)
gen_crit_loss_per_epoch.append(_gen_crit_loss)
crit_train_loss_per_epoch = np.mean(np.array(crit_train_loss_per_epoch))
gen_train_loss_per_epoch = np.mean(np.array(gen_train_loss_per_epoch))
gen_norm_loss_per_epoch = np.mean(np.array(gen_norm_loss_per_epoch))
gen_crit_loss_per_epoch = np.mean(np.array(gen_crit_loss_per_epoch))
crit_test_loss_per_epoch = []
gen_test_loss_per_epoch = []
for test_batch in test_dataloader:
test_batch = test_batch.to(device)
random_encodings = torch.randn((train_batch.shape[0], latent_dim)).to(device)
# start with critique testing
_crit_test_loss = crit_test_step(train_batch, random_encodings)
_crit_test_loss = _crit_test_loss.detach().cpu().numpy()
crit_test_loss_per_epoch.append(_crit_test_loss)
# now test the generator
_gen_loss, _, _ = gen_test_step(random_encodings)
_gen_loss = _gen_loss.detach().cpu().numpy()
gen_test_loss_per_epoch.append(_gen_loss)
crit_test_loss_per_epoch = np.mean(np.array(crit_test_loss_per_epoch))
gen_test_loss_per_epoch = np.mean(np.array(gen_test_loss_per_epoch))
if epoch % weight_save_interval == 0 and save_weights == True:
torch.save(critique.state_dict(), "results/weights/critique_weights_epoch_{}".format(epoch))
torch.save(generator.state_dict(), "results/weights/generator_weights_epoch_{}".format(epoch))
plot_gan_outputs(generator, epoch, n=5)
loss_history["gen train"].append(gen_train_loss_per_epoch)
loss_history["gen test"].append(gen_test_loss_per_epoch)
loss_history["crit train"].append(crit_train_loss_per_epoch)
loss_history["crit test"].append(crit_test_loss_per_epoch)
loss_history["gen crit"].append(gen_crit_loss_per_epoch)
loss_history["gen norm"].append(gen_norm_loss_per_epoch)
print ('epoch {} : gen train: {:01.4f} gen test: {:01.4f} crit train {:01.4f} crit test {:01.4f} gen norm {:01.4f} gen crit {:01.4f} time {:01.2f}'.format(epoch + 1, gen_train_loss_per_epoch, gen_test_loss_per_epoch, crit_train_loss_per_epoch, crit_test_loss_per_epoch, gen_norm_loss_per_epoch, gen_crit_loss_per_epoch, time.time()-start))
return loss_historyAs in the image generating example, the training function calls after each epoch a function to visually verify the progress of the training. This function draws an image in which several synthetic poses generated by the Generator are placed in a row. The function employs an instance of the PoseRenderer class to render the synthetic poses. The function takes as arguments the Generator model, the current epoch, and the number of poses that the Generator should generate. This function is defined as follows.
def plot_gan_outputs(generator, epoch, n=5):
generator.eval()
plt.figure(figsize=(10,4.5))
zero_trajectory = torch.tensor(np.zeros((1, 1, 3), dtype=np.float32))
zero_trajectory = zero_trajectory.to(device)
for i in range(n):
ax = plt.subplot(1,n,i+1)
random_encoding = torch.randn((1, latent_dim)).to(device)
with torch.no_grad():
gen_pose = generator(random_encoding)
gen_pose = torch.squeeze(gen_pose)
gen_pose = gen_pose.view((-1, 4))
gen_pose = nn.functional.normalize(gen_pose, p=2, dim=1)
gen_pose = gen_pose.view((1, 1, joint_count, joint_dim))
skel_pose = skeleton.forward_kinematics(gen_pose, zero_trajectory)
skel_pose = skel_pose.detach().cpu().numpy()
skel_pose = np.reshape(skel_pose, (1, joint_count, 3))
view_min, view_max = utils.get_equal_mix_max_positions(skel_pose)
pose_image = poseRenderer.create_pose_images(skel_pose, view_min, view_max, view_ele, view_azi, view_line_width, view_size, view_size)
plt.imshow(pose_image[0])
ax.get_xaxis().set_visible(False)
ax.get_yaxis().set_visible(False)
if i == 0:
ax.set_title("Epoch {}: Generated Images".format(epoch))
plt.show()
generator.train()The “train” function can be called as follows:
loss_history = train(train_dataloader, test_dataloader, epochs)Generate and Visualise Poses
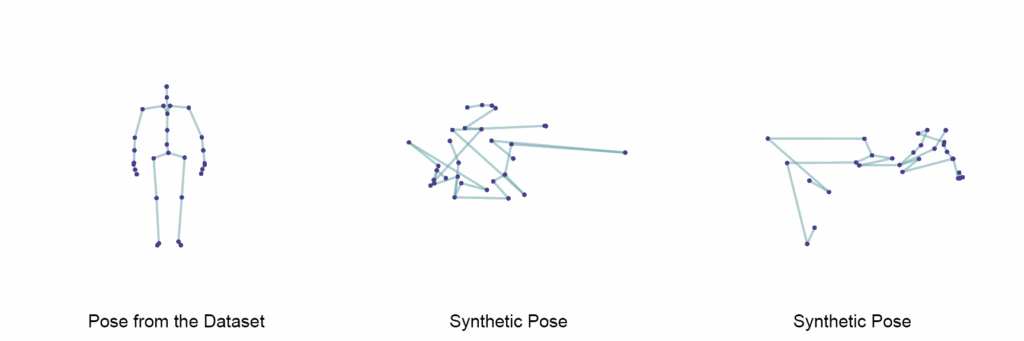
Two convenience functions are defined for rendering poses as graphical images. The images are exported in “.gif” format.
The first function named “create_ref_pose_image” creates an image of a pose that is obtained from the original motion capture data. This function takes as arguments an index of the frame in a pose sequence and the name of the file the image is exported as.
def create_ref_pose_image(pose_index, file_name):
pose = poses[pose_index]
pose = torch.tensor(np.reshape(pose, (1, 1, joint_count, joint_dim))).to(device)
zero_trajectory = torch.tensor(np.zeros((1, 1, 3), dtype=np.float32)).to(device)
skel_pose = skeleton.forward_kinematics(pose, zero_trajectory)
skel_pose = skel_pose.detach().cpu().numpy()
skel_pose = np.reshape(skel_pose, (joint_count, 3))
view_min, view_max = utils.get_equal_mix_max_positions(skel_pose)
pose_image = poseRenderer.create_pose_image(skel_pose, view_min, view_max, view_ele, view_azi, view_line_width, view_size, view_size)
pose_image.save(file_name, optimize=False)The second function named “create_gen_pose_image” creates an image of a synthetic pose that is generated by the Generator. This function takes as single argument the name of the file the image is exported as.
def create_gen_pose_image(file_name):
generator.eval()
random_encoding = torch.randn((1, latent_dim)).to(device)
with torch.no_grad():
gen_pose = generator(random_encoding)
gen_pose = torch.squeeze(gen_pose)
gen_pose = gen_pose.view((-1, 4))
gen_pose = nn.functional.normalize(gen_pose, p=2, dim=1)
gen_pose = gen_pose.view((1, 1, joint_count, joint_dim))
zero_trajectory = torch.tensor(np.zeros((1, 1, 3), dtype=np.float32))
zero_trajectory = zero_trajectory.to(device)
skel_pose = skeleton.forward_kinematics(gen_pose, zero_trajectory)
skel_pose = skel_pose.detach().cpu().numpy()
skel_pose = np.squeeze(skel_pose)
view_min, view_max = utils.get_equal_mix_max_positions(skel_pose)
pose_image = poseRenderer.create_pose_image(skel_pose, view_min, view_max, view_ele, view_azi, view_line_width, view_size, view_size)
pose_image.save(file_name, optimize=False)
generator.train()These two functions can be called as follows:
pose_index = 100
create_ref_pose_image(pose_index, "results/images/orig_pose_{}.gif".format(pose_index))
create_gen_pose_image("results/images/gen_pose.gif")