Summary
Granular Dance is a tool that can be trained with motion capture data and then used to generate new dance movement sequences. Granular Dance combines two different components: a deep learning model based on a recurrent adversarial autoencoder architecture, and a sequence blending mechanism that is inspired by granular and concatenative sound synthesis techniques.
A detailed description of the project has been published.
Machine Learning Model
The model consists of an encoder, decoder, and discriminator. The autoencoder part operates on sequence of poses in which each pose is represented by joint orientations in the form of unit quaternions. The discriminator takes as input a latent encoding of a pose sequence and generates as output an estimate whether the encoding follows a Gaussian prior distribution.
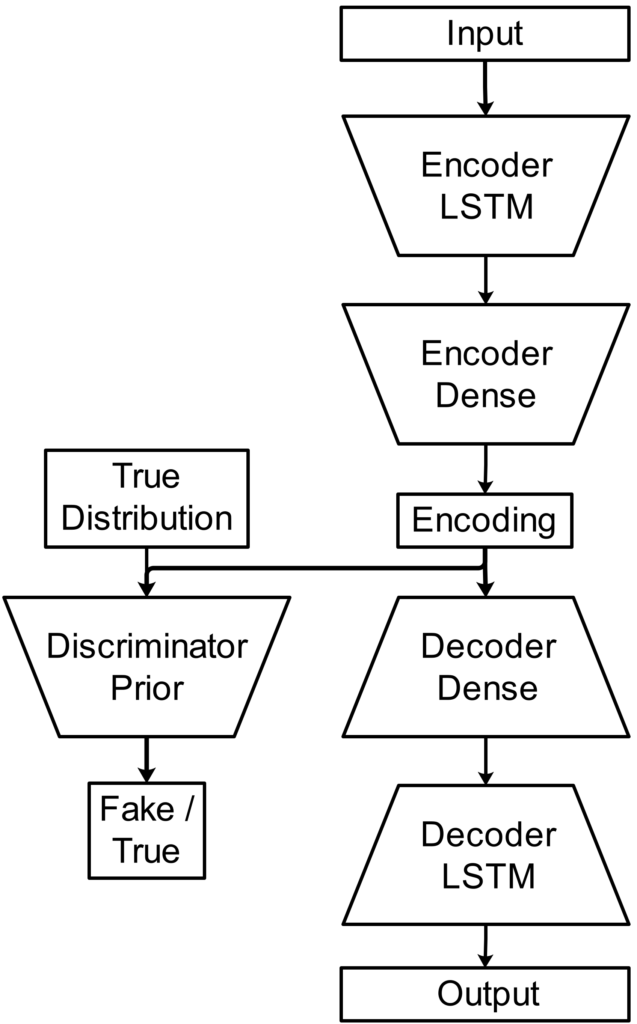
Sequence Blending
The sequence blending mechanism is inspired by two methods from computer music that combine short sound fragments to generate longer sounds: Granular Synthesis and Concatenative Synthesis. For this project, the sequence blending mechanism is used to combine short pose sequences generated by the decoder into longer pose sequences. Similar to Granular Synthesis, a window function is superimposed on the pose sequence which in this case blends the joint orientations of the overlapping pose sequences by spherical linear interpolation.
Dataset
Training data for machine learning was acquired using a marker-less motion capture system. The recording was conducted at MotionBank, University for Applied Research Mainz. The recorded subjects were professional dancers specialized in contemporary dance. The recording used for training was taken from a single male dancer who was freely improvising to excerpts of music including experimental electronic music, free jazz, and contemporary classic.
Latent Space Navigation
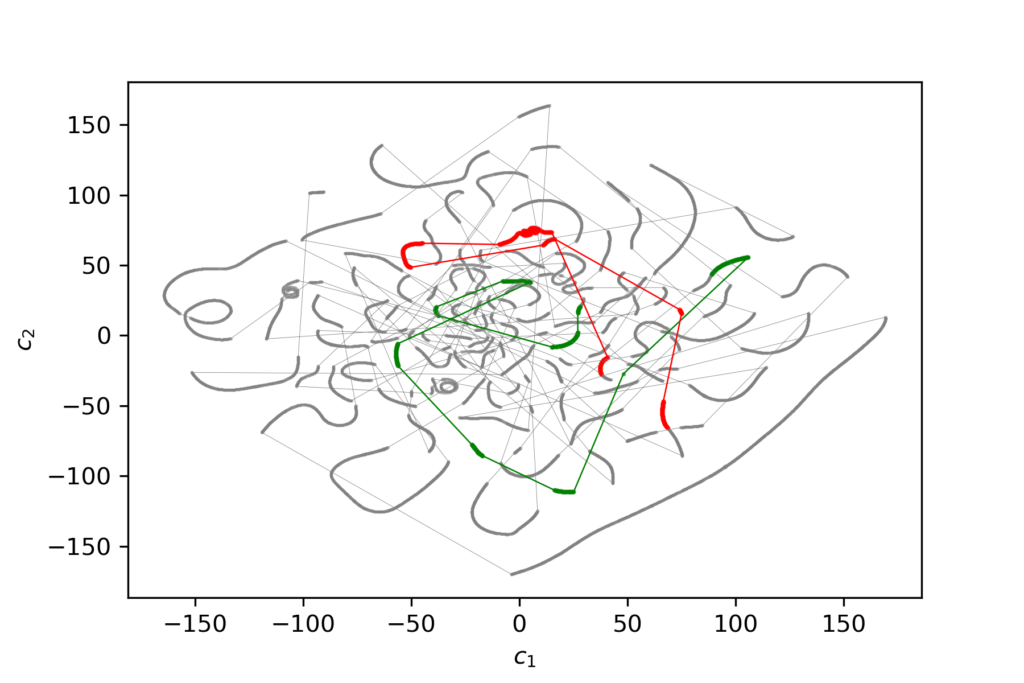
A popular approach of using autoencoders for the purpose of movement generation is to navigate through latent space and collect latent vectors along the way which are then decoded and concatenated into a sequence. Several latent space navigation experiments have been conducted: random walk, trajectory offset following, trajectory interpolation. For these experiments, two types of machine learning models have been employed. A model named model128 works with sequences of 128 poses and an encoding dimension of 64. Another model named model8 works with sequences of 8 poses and an encoding dimension of 16.